Did you know that files with the extension .docx are really just .zip packages? I knew that’s essentially what .apk files (Android Package) were but I never really made the connection that this could apply to other common file types as well.
But I recently came across an issue where a document I had spent a significant amount of time on was corrupted. No matter, right? Just grab the backup. Unfortunately, I had overwritten my backed up copy with the corrupted version of the file.
🤦
If I couldn’t find a way to recover it, I would have had to reproduce my changes all over again, effectively doubling my work.
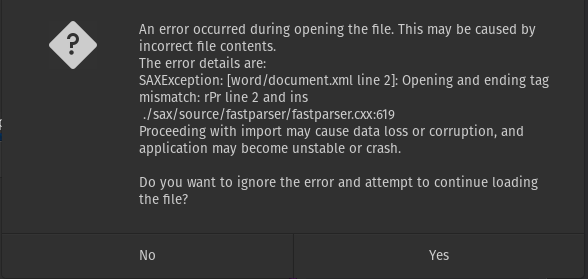
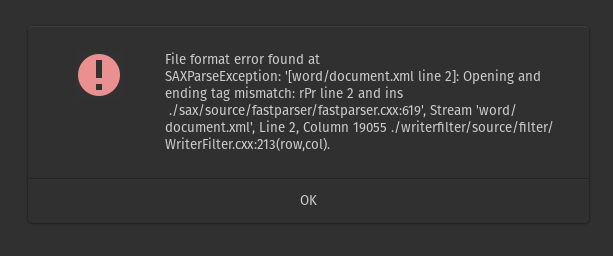
Fortunately, I am very good at finding information on the Internet and so after a brief search, I came across this thread in the LibreOffice forums:
Take a copy of the ODT and open the copy using an archive manager (rename the file to a
.zipextension if necessary). Extract thecontent.xmlfile. Open this file with a suitable XML editor. It will be likely that row 2 contains a very long line of XML. Scroll to character 18067. It is likely at this point there will be an obvious mistake in the XML. It may be minor or major. Once you fix it, simple reinsert the fixed version ofcontent.xmlinto the ODT copy, again using an archive manager. Try and open the amended ODT using LO.oweng – https://ask.libreoffice.org/t/how-do-i-fix-a-libreoffice-document-that-is-corrupted/17399/2
If .odt files are packages of XML files, it seems likely that .docx files are as well, right? Turns out, they are! It is possible to simply change the extension of the document to .zip. From that point, the archived files can be opened and browsed like any normal directory and I can use the information provided in previous error prompts to locate the troublesome XML. The error prompt showed that issue was located in the file word/document.xml on line 2, column 19055. Sure enough, when going there, I found the following:
<w:rPr><w:del w:id="9" w:author="Dylan Hildenbrand" w:date="2023-02-13T14:15:30Z"></w:del></w:ins></w:rPr>Removing the extra closing tag </w:ins>, saving the file, and renaming the .zip back to a .docx resolved this issue for me. My file was recovered and precious hours were not wasted. And yes dear reader, the irony of finding an extra closing tag that could have cost me several hours is not lost on me; the operator of a website titled closingtags.com.

2 replies on “Recovering Corrupted .docx Files”
Yes! The triumph of recovering data, and time, must have been fantastic.
Very nice of LibreOffice to offer such a specific error message. I wonder if MS Word would provide the same?
Great post, man.
It was a feeling of great success. I had to share it in case anyone else came across a similar problem.
As for Office, I have no clue what it offers these days. Switched to LibreOffice and haven’t looked back.
Thanks for the comment!